The Splunk Cloud Certified Admin (SPLK-1005) exam validates your ability to manage, configure, and support Splunk Cloud environments in production. This certification is ideal for IT administrators, cloud engineers, and Splunk practitioners who work with cloud-based data analytics and security monitoring. This page provides a comprehensive study roadmap covering the exam syllabus, question formats, and actionable preparation strategies to help you pass with confidence.
Use this topic map to guide your study for Splunk SPLK-1005 (Splunk Cloud Certified Admin) within the Splunk Cloud Certified Admin path.
The SPLK-1005 exam uses multiple question types to assess both foundational knowledge and practical decision-making in cloud administration scenarios. Questions progress in difficulty and reflect real-world situations you will encounter managing Splunk Cloud deployments.
Effective preparation requires a structured approach that maps exam topics to weekly study goals and reinforces connections between concepts. Dedicate 4-6 weeks to study, allocating time proportionally to topic complexity and your current knowledge gaps. Combine theoretical learning with hands-on practice in a Splunk Cloud trial environment.
Strengthen your preparation with up-to-date resources from validexamdumps.com. These materials align to SPLK-1005 and cover practical scenarios with clear explanations.
Visit the exam page to download the PDF, Online Practice Test, or get a bundle discount for both formats: Splunk Cloud Certified Admin.
Index Management, User Authentication and Authorization, and Getting Data in Cloud typically represent the largest portion of exam questions. These topics form the foundation of daily cloud administration tasks. However, all syllabus topics are fair game, so balanced preparation across all domains is essential.
Data flows through multiple stages: you configure inputs (Monitor Inputs, Network and Other Inputs) to collect data, fine-tune input settings for performance, apply parsing rules during the Parsing Phase, use Manipulating Raw Data techniques to transform events, and finally store them in indexes managed through Index Management. Understanding this pipeline helps you troubleshoot issues at any stage and make informed configuration decisions.
At least 6-12 months of experience managing Splunk Cloud environments is recommended. Hands-on labs are crucial; prioritize setting up forwarders, configuring inputs, managing users and roles, and working with configuration files in a trial environment. Practical experience with real data ingestion challenges significantly improves exam performance.
Many candidates confuse on-premise Splunk with cloud-specific features and limitations, overlook the importance of proper sourcetype and host assignment during input setup, and misunderstand role-based access control nuances. Additionally, candidates often rush scenario questions without fully analyzing the problem context. Read each question carefully, consider all options, and apply cloud-specific best practices.
Focus on full-length timed practice tests to build pacing and confidence. Review any topics where practice test results show gaps, but avoid deep dives into new material. Get adequate sleep, maintain a study schedule, and do a light review of key definitions and configuration syntax the day before the exam. Trust your preparation and manage test anxiety through controlled breathing and time management during the actual exam.
The following Apache access log is being ingested into Splunk via a monitor input:

How does Splunk determine the time zone for this event?
In Splunk, when ingesting logs such as an Apache access log, the time zone for each event is typically determined by the time zone indicator present in the raw event data itself. In the log snippet you provided, the time zone is indicated by -0400, which specifies that the event's timestamp is 4 hours behind UTC (Coordinated Universal Time).
Splunk uses this information directly from the event to properly parse the timestamp and apply the correct time zone. This ensures that the event's time is accurately reflected regardless of the time zone in which the Splunk instance or forwarder is located.
Splunk Cloud Reference: For further details, you can review Splunk documentation on timestamp recognition and time zone handling, especially in relation to log files and data ingestion configurations.
Source:
Splunk Docs: How Splunk software handles timestamps
Splunk Docs: Configure event timestamp recognition
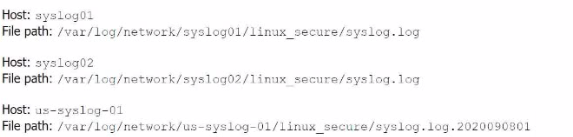
Li was asked to create a Splunk configuration to monitor syslog files stored on Linux servers at their organization. This configuration will be pushed out to multiple systems via a Splunk app using the on-prem deployment server.
The system administrators have provided Li with a directory listing for the logging locations on three syslog hosts, which are representative of the file structure for all systems collecting this dat
a. An example from each system is shown below:
A)

B)

C)
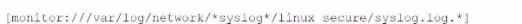
D)

The correct monitor statement that will capture all variations of the syslog file paths across different systems is [monitor:///var/log/network/syslog*/linux_secure/*].
This configuration works because:
syslog* matches directories that start with 'syslog' (like syslog01, syslog02, etc.).
The wildcard * after linux_secure/ will capture all files within that directory, including different filenames like syslog.log and syslog.log.2020090801.
This setup will ensure that all the necessary files from the different syslog hosts are monitored.
Splunk Documentation Reference: Monitor files and directories
When adding a directory monitor and specifying a sourcetype explicitly, it applies to all files in the directory and subdirectories. If automatic sourcetyping is used, a user can selectively override it in which file on the forwarder?
When a directory monitor is set up with automatic sourcetyping, a user can selectively override the sourcetype assignment by configuring the props.conf file on the forwarder. The props.conf file allows you to define how data should be parsed and processed, including assigning or overriding sourcetypes for specific data inputs.
Splunk Documentation Reference: props.conf configuration
What two files are used in the data transformation process?
props.conf and transforms.conf define data parsing, transformations, and routing rules, making them essential for data transformations. [Reference: Splunk Docs on props.conf and transforms.conf]
Which of the following are valid settings for file and directory monitor inputs?
A)
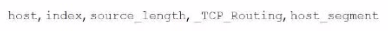
B)

C)

D)

In Splunk, when configuring file and directory monitor inputs, several settings are available that control how data is indexed and processed. These settings are defined in the inputs.conf file. Among the given options:
host: Specifies the hostname associated with the data. It can be set to a static value, or dynamically assigned using settings like host_regex or host_segment.
index: Specifies the index where the data will be stored.
sourcetype: Defines the data type, which helps Splunk to correctly parse and process the data.
TCP_Routing: Used to route data to specific indexers in a distributed environment based on TCP routing rules.
host_regex: Allows you to extract the host from the path or filename using a regular expression.
host_segment: Identifies the segment of the directory structure (path) to use as the host.
Given the options:
Option B is correct because it includes host, index, sourcetype, TCP_Routing, host_regex, and host_segment. These are all valid settings for file and directory monitor inputs in Splunk.
Splunk Documentation Reference:
Monitor Inputs (inputs.conf)
Host Setting in Inputs
TCP Routing in Inputs
By referring to the Splunk documentation on configuring inputs, it's clear that Option B aligns with the valid settings used for file and directory monitoring, making it the correct choice.