The Qlik Sense Data Architect Certification Exam - 2024 (QSDA2024) validates your ability to design, build, and optimize data architectures within Qlik Sense. This exam is designed for data professionals, architects, and developers who work with Qlik to create scalable, efficient data models and transformation pipelines. This page provides a clear roadmap of exam topics, question formats, and practical preparation strategies to help you succeed. Whether you're new to Qlik Sense or deepening your expertise, understanding the exam structure and content areas is the first step toward confident performance.
Use this topic map to guide your study for Qlik QSDA2024 (Qlik Sense Data Architect Certification Exam - 2024) within the Qlik Sense path.
The QSDA2024 exam uses a mix of question types to assess both conceptual knowledge and applied reasoning in real-world Qlik Sense scenarios. Questions progress in difficulty and require you to think beyond memorization to solve practical architecture challenges.
Questions are designed to reflect the complexity and decision-making you encounter in production Qlik Sense environments.
A structured study plan focused on the five core topics ensures you build confidence and competence across the full exam scope. Allocate time proportionally to each domain, practice with realistic scenarios, and review weak areas systematically. The key is to connect each topic to real project workflows so concepts stick and transfer to your role.
Explore other Qlik certifications: view all Qlik exams.
Strengthen your preparation with up-to-date resources from validexamdumps.com. These materials align to QSDA2024 and cover practical scenarios with clear explanations.
Visit the exam page to download the PDF, Online Practice Test, or get a Bundle Discount offer for both formats: Qlik Sense Data Architect Certification Exam - 2024.
Data Model Design and Data Transformations typically account for a larger portion of exam items because they are central to a data architect's daily work in Qlik Sense. However, all five topics are important; a balanced study plan ensures you are not caught off guard by questions in any domain.
In practice, they form a workflow: you start by identifying business and technical requirements, then configure data sources through connectivity, design the logical model, apply transformations to prepare data, and finally validate quality before deployment. Understanding these connections helps you see why each topic matters and how decisions in one area affect others.
Ideally, you should have 6-12 months of practical experience building data models and scripts in Qlik Sense. If you are newer to the platform, prioritize hands-on labs in data connectivity and transformations; these skills are harder to learn from study materials alone and are heavily tested on the exam.
Many candidates underestimate the importance of data validation and quality checks, focusing instead on model design alone. Others miss nuances in scenario questions by not reading the full context or requirements carefully. Finally, some struggle with transformation logic because they lack hands-on scripting practice; review actual Qlik Sense script examples and build small models yourself.
Shift from learning new material to reviewing weak areas and taking full-length practice tests. Use timed practice exams to build pacing and identify which question types slow you down. On the last two days, do a light review of key definitions and architecture patterns rather than cramming new content.
Refer to the exhibit.
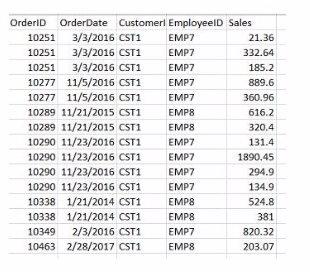
A data architect needs to build a dashboard that displays the aggregated sates for each sales representative. All aggregations on the data must be performed in the script.
Which script should the data architect use to meet these requirements?
A)

B)

C)

D)

The goal is to display the aggregated sales for each sales representative, with all aggregations being performed in the script. Option C is the correct choice because it performs the aggregation correctly using a Group by clause, ensuring that the sum of sales for each employee is calculated within the script.
Data Load:
The Data table is loaded first from the Sales table. This includes the OrderID, OrderDate, CustomerID, EmployeeID, and Sales.
Next, the Emp table is loaded containing EmployeeID and EmployeeName.
Joining Data:
A Left Join is performed between the Data table and the Emp table on EmployeeID, enriching the data with EmployeeName.
Aggregation:
The Summary table is created by loading the EmployeeName and calculating the total sales using the sum([Sales]) function.
The Resident keyword indicates that the data is pulled from the existing tables in memory, specifically the Data table.
The Group by clause ensures that the aggregation is performed correctly for each EmployeeName, summarizing the total sales for each employee.
Key Qlik Sense Data Architect Reference:
Resident Load: This is a method to reuse data that is already loaded into the app's memory. By using a Resident load, you can create new tables or perform calculations like aggregation on the existing data.
Group by Clause: The Group by clause is essential when performing aggregations in the script. It groups the data by specified fields and performs the desired aggregation function (e.g., sum, count).
Left Join: Used to combine data from two tables. In this case, Left Join is used to enrich the sales data with employee names, ensuring that the sales data is associated correctly with the respective employee.
Conclusion: Option C is the most appropriate script for this task because it correctly performs the necessary joins and aggregations in the script. This ensures that the dashboard will display the correct aggregated sales per employee, meeting the data architect's requirements.
A data architect inherits an app that takes too long to load and overruns the data load window.
The app pulls all records (new and historical) from three large databases. The reload process puts a heavy load on the source database servers. All of the data is required for analysis.
What should the data architect do?
The scenario describes an app that is experiencing long load times due to the need to pull all records, both new and historical, from three large databases. This situation puts a strain on both the Qlik environment and the source databases. Given that all data is required for analysis, a full reload each time can be inefficient and resource-intensive.
Implementing incremental load is a widely recommended approach in such cases. Incremental loading allows you to load only new or changed data since the last reload, rather than reloading all the data every time. This significantly reduces the time and resources required for reloading, as only a subset of the data needs to be processed during each reload. QVD (QlikView Data) files are typically used to store the historical data, while only the new or updated records are fetched from the source databases.
This approach would help:
Reduce the load on the source databases.
Shorten the data reload window.
Maintain historical data efficiently while ensuring that all new data is captured.
The data architect has been tasked with building a sales reporting application.
* Part way through the year, the company realigned the sales territories
* Sales reps need to track both their overall performance, and their performance in their current territory
* Regional managers need to track performance for their region based on the date of the sale transaction
* There is a data table from HR that contains the Sales Rep ID, the manager, the region, and the start and end dates for that assignment
* Sales transactions have the salesperson in them, but not the manager or region.
What is the first step the data architect should take to build this data model to accurately reflect performance?
In the provided scenario, the sales territories were realigned during the year, and it is necessary to track performance based on the date of the sale and the salesperson's assignment during that period. The IntervalMatch function is the best approach to create a time-based relationship between the sales transactions and the sales territory assignments.
IntervalMatch: This function is used to match discrete values (e.g., transaction dates) with intervals (e.g., start and end dates for sales territory assignments). By matching the transaction dates with the intervals in the HR table, you can accurately determine which territory and manager were in effect at the time of each sale.
Using IntervalMatch, you can generate point-in-time data that accurately reflects the dynamic nature of sales territory assignments, allowing both sales reps and regional managers to track performance over time.
A data architect needs to write the expression for a measure on a KPI to show the sales person with the highest sales. The sort order of the values of the fields is unknown. When two or more sales people have sold the same amount, the expression should return all of those sales people.
Which expression should the data architect use?
A)

B)

C)
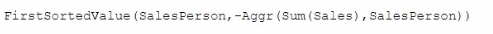
D)

The requirement is to create a measure that identifies the salesperson with the highest sales. If multiple salespeople have the same highest sales amount, the measure should return all of those salespeople.
Explanation of Option A:
Rank(Sum(Sales), 1): The Rank() function is used to rank salespersons based on the sum of their sales. The rank 1 indicates the top position.
Aggr() Function: This function aggregates the data and returns the results grouped by the SalesPerson field.
IF() Condition: The IF condition checks if the salesperson's rank is 1 (highest sales).
Concat(DISTINCT ...): The Concat() function concatenates all the salespersons who have the highest sales, separated by spaces or another delimiter, ensuring that all top performers are returned.
Example:
If three salespersons have the highest sales, this expression will return all three names separated by a space.
Exhibit.
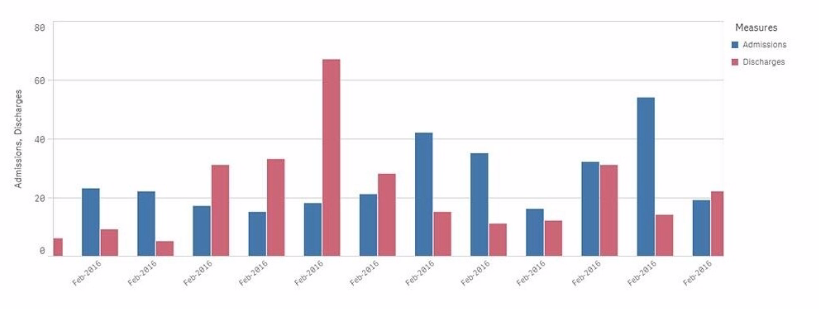
A chart for monthly hospital admissions and discharges incorrectly displays the month and year values on the x-axis.
The date format for the source data field "Common Date" is M/D/YYYY. This format was used in a calculated field named "Month-Year" in the data manager when the data model was first built.
Which expression should the data architect use to fix this issue?
The issue described relates to the incorrect display of month and year values on the x-axis of a chart. The source data has dates in the M/D/YYYY format, and a calculated field named Month-Year was created using this date format.
To correct the issue:
The correct approach is to use the MonthStart() function, which returns the first date of the month for the provided date. This ensures consistency in month-year representation.
The Date() function is then used to format the result of MonthStart() to the desired format of MMM-YYYY (e.g., Feb-2018).
Explanation of the Correct Expression:
MonthStart([Common Date]): This ensures that all dates within a month are treated as the first day of that month, which is critical for accurate monthly aggregation.
Date(..., 'MMM-YYYY'): This formats the result to show just the month and year in the correct format.
Using this expression ensures that the x-axis correctly displays the month-year values.