The NS0-593 exam validates your expertise as a NetApp Certified Support Engineer with a focus on ONTAP specialist capabilities. This certification demonstrates your ability to support, troubleshoot, and optimize NetApp storage environments in production settings. Whether you're advancing your career in storage infrastructure or deepening your technical knowledge of ONTAP systems, this page provides a clear roadmap for exam preparation. Use the syllabus, study strategies, and practice resources below to build confidence and competency across all tested domains.
Use this topic map to guide your study for NetApp NS0-593 (NetApp certified support engineer - ONTAP specialist) within the NetApp Certified Support Engineer path.
The NS0-593 exam uses multiple question types to assess both theoretical knowledge and practical decision-making ability. Questions progress in difficulty and reflect real-world support scenarios you will encounter.
Effective preparation requires mapping exam topics to a structured study plan and reinforcing learning through practice. Allocate time proportionally to each domain, focusing on areas where you have less hands-on experience. Combine conceptual study with scenario-based practice to build the reasoning skills the exam measures.
Explore other NetApp certifications: view all NetApp exams.
Strengthen your preparation with up-to-date resources from validexamdumps.com. These materials align to NS0-593 and cover practical scenarios with clear explanations.
Visit the exam page to download the PDF, Online Practice Test or get Bundle Discount offer for both formats: NetApp certified support engineer - ONTAP specialist.
ONTAP OS fundamentals and Protocols usually account for a larger portion of the exam, reflecting their importance in daily support work. However, all five domains are tested, so balanced preparation across all topics is essential. Review the official exam blueprint to confirm current topic weightings.
Hardware choices directly influence performance characteristics; for example, controller model determines I/O throughput capacity, and disk type affects latency profiles. In production troubleshooting, you must correlate hardware specifications with performance metrics to identify whether slowness stems from configuration, workload, or physical constraints. Understanding this connection helps you make sound recommendations for capacity upgrades and optimization.
While hands-on experience strengthens your understanding, the exam is designed for candidates with varying levels of practical exposure. Prioritize labs that cover cluster setup, protocol configuration (NFS and CIFS), basic performance monitoring, and snapshot/replication workflows. If you lack production access, use NetApp's free trial environments or simulation tools to gain familiarity with command-line interfaces and system navigation.
Candidates often misread scenario details and jump to conclusions without analyzing all symptoms. Another frequent error is confusing similar features (for example, SnapMirror vs. SnapVault) or applying best practices from one protocol to another where they don't apply. Read each question carefully, eliminate obviously wrong answers first, and reason through the context before selecting your response.
Use your final week to review weak areas identified in practice tests rather than re-studying strong topics. Take one more full-length timed practice test to validate your readiness and build confidence. Spend the last few days doing quick refresher reviews of high-yield concepts and command syntax, then rest well the night before your exam to ensure mental clarity.
A storage administrator reports that a monitoring toot is reporting that the storage controller reads between 90% to 93% CPU use. You run the sysstat -m command against the node in question.
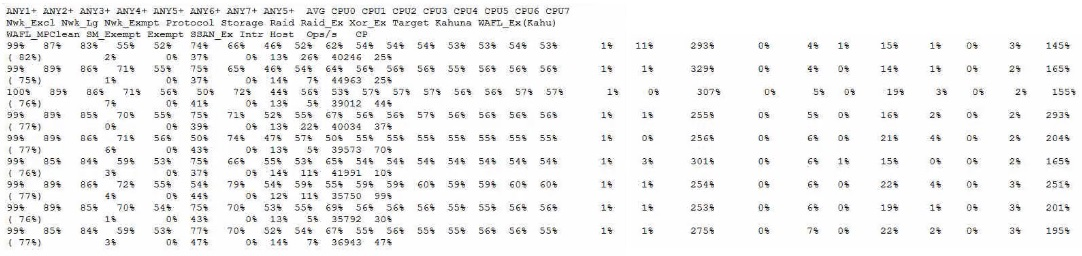
Referring to the exhibit, which statement is correct?
= CPU utilization in ONTAP is not a linear measure of the system load, nor can it be used alone as a measure of the overall system utilization. ONTAP uses a Coarse Symmetric Multiprocessing (CSMP) design which partitions system functions into logical processing domains, each with its own scheduling rules and resource availability. Therefore, a high CPU utilization does not necessarily indicate a performance problem, unless it is accompanied by other contributing factors such as high latency, low throughput, or high queue depth. ONTAP has several mechanisms to optimize CPU usage and balance the workload across the cores, such as WAFL parallelization, exempt processing, and CPU pinning. The CPU utilization reported by the sysstat command is an average across all cores and domains, and does not reflect the actual CPU activity or availability for each domain. Therefore, the CPU is not a first-order monitoring metric for ONTAP, and other metrics such as latency, throughput, and queue depth should be considered first.Reference=What is CPU utilization in Data ONTAP: Scheduling and Monitoring?,How to measure CPU utilization,What are CPU as a compute resource and the CPU domains in ONTAP 9?,Monitoring CPU utilization before ONTAP upgrade
You have recently discovered that NetApp ONTAP Cloud Manager is not sending AutoSupport messages to NetApp.
In this scenario, what would solve this Issue?
= AutoSupport is enabled by default for Cloud Manager and ONTAP Cloud systems. It proactively monitors the health of your systems and sends messages to NetApp technical support. To enable AutoSupport, you must provide your NetApp Support site credentials to Cloud Manager. If your credentials are incorrect or expired, Cloud Manager will not be able to send AutoSupport messages to NetApp. Therefore, the solution for this issue is to verify that your NetApp Support site credentials are correctly added to Cloud Manager.Reference=Troubleshooting Cloud Manager and ONTAP Cloud,Set up AutoSupport
Your customer installed the shelf firmware for their NS224 shelf over a week ago, and the firmware has not upgraded on shelf 1 module B. The customer wants to know what the next steps would be to get the firmware upgraded after verifying that the shelf firmware is indeed loaded onto the system.
Which step would you perform to complete the firmware upgrade?
The question refers to a scenario where the shelf firmware for an NS224 shelf has not been upgraded on one of the NVMe shelf modules (NSM) after a week of installation.
The NSM is responsible for managing the communication between the drives and the I/O modules (IOM) in the shelf1.
The shelf firmware for the NSM is automatically updated when the NSM is inserted into the shelf or when the system is rebooted2.
If the automatic update does not work, the manual update process involves reseating the NSM, which means removing it from the shelf and inserting it back3.
Reseating the NSM triggers the firmware update and also resets the NSM's state3.
The other options are not correct, because:
B)Reseating the disk in Bay 0 will not affect the NSM firmware update, as the disk is not connected to the NSM1.
C)Power cycling the shelf will disrupt the I/O operations and may cause data loss or corruption4.
D)Reseating the PSU of the shelf will not affect the NSM firmware update, as the PSU is not connected to the NSM1.Reference:
NS224 NVMe drive shelf overview - NetApp
Shelf firmware update process - NetApp
Module firmware upgrade stuck on NS224 shelf - NetApp Knowledge Base
Power cycle a disk shelf - NetApp
An administrator receives the following error message:

What are two causes for this error? (Choose two.)
The error message ''wafl.cp.toolong:error'' indicates that a WAFL consistency point (CP) took longer than 30 seconds to complete. A CP is a process that flushes the data from the NVRAM buffer to the disk.A long CP can cause latency and performance issues for the system1
One possible cause for a long CP is excessive SSD load causing the wear leveling to become unbalanced. Wear leveling is a technique that distributes the write operations evenly across the SSD cells to extend the lifespan of the SSD.If some SSD cells are written more frequently than others, the wear leveling will become unbalanced and the SSD performance will degrade2
Another possible cause for a long CP is an SSD disk performing garbage collection to create a dense data layout. Garbage collection is a process that reclaims the space occupied by invalid or deleted data on the SSD.Garbage collection can improve the write performance and storage efficiency of the SSD, but it can also consume CPU and disk resources and cause long CPs3
A disk failing or being failed is not a likely cause for a long CP, because the system will automatically mark the disk as failed and remove it from the aggregate.The system will also initiate a disk reconstruction or a RAID scrub to restore the data protection and redundancy4
There is no evidence that the system has SATA HDDs, so there is no reason to assume that there is excessive SATA HDD load.Moreover, SATA HDDs are usually used for secondary or backup storage, not for primary or performance-sensitive workloads5
1: Are long Consistency Points (wafl.cp.toolong) normal?- NetApp Knowledge Base2: How to troubleshoot SSD performance issues - NetApp Knowledge Base3: How to troubleshoot SSD garbage collection issues - NetApp Knowledge Base4: How to troubleshoot disk failures and replacements - NetApp Knowledge Base5: ONTAP 9 - Hardware Universe - The Open Group
You created a new NetApp ONTAP FlexGroup volume spanning six nodes and 12 aggregates with a total size of 4 TB. You added millions of files to the FlexGroup volume with a flat directory structure totaling 2 TB, and you receive an out of apace error message on your host.
What would cause this error?
The maxdirsize is the maximum size of a directory in a FlexVol or FlexGroup volume. It is determined by the number of inodes allocated to the directory. If the directory contains more files than the maxdirsize can accommodate, then the ONTAP software will return an out of space error message to the host, even if the volume has enough free space.This can happen when a FlexGroup volume has a flat directory structure with millions of files, as the maxdirsize is not automatically adjusted for FlexGroup volumes12.Reference:1: FlexGroup volumes: Frequently asked questions | NetApp Documentation2: How to increase the maxdirsize of a FlexVol volume - NetApp Knowledge Base