The DP-700 exam validates your ability to implement data engineering solutions using Microsoft Fabric. This credential is designed for data engineers who design, build, and maintain analytics platforms and data pipelines. The exam tests both conceptual knowledge and practical problem-solving skills across the Fabric Data Engineer Associate certification path. This page outlines the exam structure, core topics, and effective preparation strategies to help you succeed on your first attempt.
Use this topic map to guide your study for Microsoft DP-700 (Implementing Data Engineering Solutions Using Microsoft Fabric) within the Fabric Data Engineer Associate path.
The DP-700 exam uses multiple question types to assess both theoretical understanding and applied reasoning in real-world data engineering scenarios.
Questions progress in difficulty and emphasize practical application over memorization, reflecting the skills needed in production environments.
An effective study plan maps the three core topics to weekly milestones and includes regular practice with realistic scenarios. Allocate more time to areas where you lack hands-on experience, and use practice tests to identify weak points early.
Explore other Microsoft certifications: view all Microsoft exams.
Strengthen your preparation with up-to-date resources from validexamdumps.com. These materials align to DP-700 and cover practical scenarios with clear explanations.
Visit the exam page to download the PDF, Online Practice Test, or get a Bundle Discount offer for both formats: Implementing Data Engineering Solutions Using Microsoft Fabric.
While all three domains are important, ingest and transform data and monitor and optimize an analytics solution typically represent larger portions of the exam. Focus on building strong fundamentals in data pipeline design and performance troubleshooting, as these skills are critical in most data engineering roles and appear frequently in scenario-based questions.
In practice, these topics form a continuous cycle: you ingest and transform data according to business requirements, implement the analytics solution with proper governance and structure, then monitor performance and optimize based on actual usage patterns. Understanding these connections helps you make design decisions that support the entire lifecycle rather than optimizing for a single phase.
Ideally, you should complete at least 3-4 weeks of practical work in Fabric workspaces, including building a simple end-to-end pipeline, creating semantic models, and configuring security. Hands-on experience significantly improves your ability to recognize correct answers in scenario-based questions and helps you avoid common implementation mistakes.
Frequent errors include overlooking security implications in solution design, misunderstanding the differences between Fabric components (lakehouses vs. warehouses), and choosing inefficient transformation approaches. Many candidates also rush through scenario questions without fully analyzing requirements, leading to suboptimal design choices. Take time to read each question carefully and consider trade-offs between solutions.
In the final week, review your practice test results to identify patterns in missed questions rather than re-reading all study materials. Take a full-length timed mock exam to build confidence and refine your pacing strategy. Spend the last few days reviewing high-weight topics and ensuring you can quickly recall key Fabric features, transformation patterns, and optimization techniques without overthinking.
You need to ensure that WorkspaceA can be configured for source control. Which two actions should you perform?
Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
You have a Fabric workspace that contains a lakehouse named Lakehouse1. Lakehouse1 contains a table named Table 1. You need to ensure that a user named User 1 can view only specific rows in Table1. What should you do first?
You have a Fabric workspace that contains a data pipeline named Pipeline1 and a notebook named Notebook1. Pipeline1 contains an activity that is used to run Notebook1. Pipeline! is scheduled to run every 10 minutes.
You receive an alert that Pipeline! failed during the notebook execution activity.
You need to identify in which cell the failure occurred.
What should you do from Monitor in the Fabric admin center?
You have a Fabric workspace that contains a data pipeline named Pipeline! as shown in the exhibit.
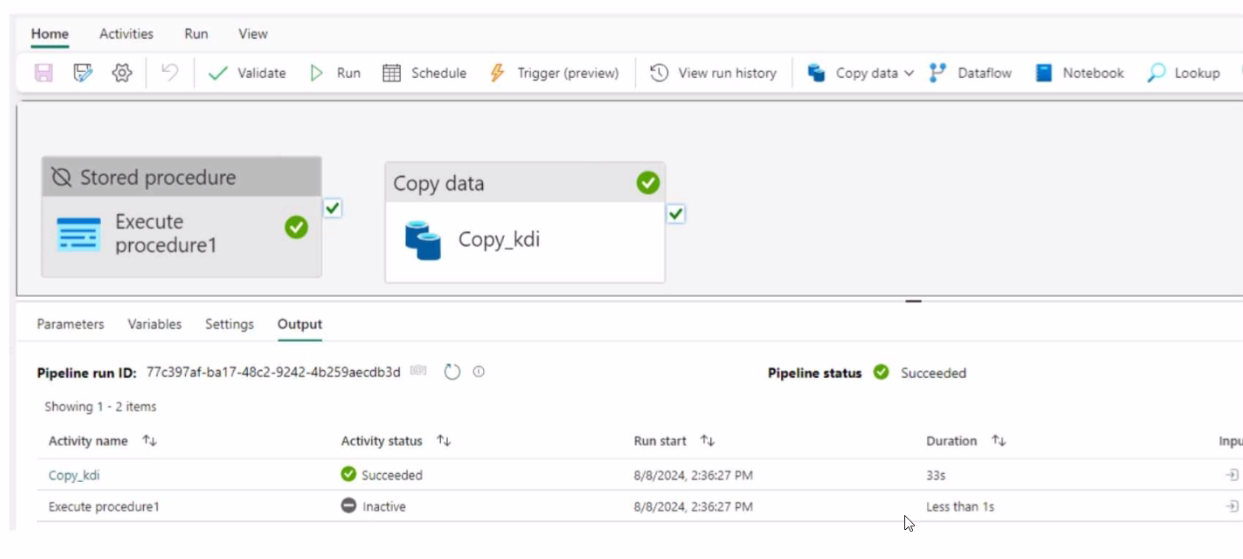
You have a Fabric warehouse named Warehouse1 that contains a table named Table1. Table 1 has a column named EmailAddress. All users have access to Warehouse1.
You need to configure dynamic data masking for the EmailAddress column. The solution must meet the following requirements:
* The solution must NOT change the data in Warehouse1.
* The solution must NOT require changes to the queries that access Table1.
* The solution must NOT require changes to the security or permissions granted to Warehouse1.
What should you use?