The DP-600 exam validates your ability to implement analytics solutions using Microsoft Fabric, a key credential for the Fabric Analytics Engineer Associate certification path. This exam tests both foundational knowledge and practical decision-making across the full analytics lifecycle. Whether you're transitioning into analytics engineering or advancing your technical skills, this page provides a structured study roadmap and resources to help you prepare efficiently. Understanding the exam's scope, question formats, and core topics is essential for confident performance on test day.
Use this topic map to guide your study for Microsoft DP-600 (Implementing Analytics Solutions Using Microsoft Fabric) within the Fabric Analytics Engineer Associate path.
The DP-600 exam combines multiple-choice items with scenario-based questions that measure both conceptual understanding and practical reasoning. Questions progress in difficulty and reflect real-world analytics engineering tasks you'll encounter on the job.
Questions reward practical thinking and an understanding of how each topic integrates into end-to-end solution delivery.
An effective study plan maps the three core topics to weekly milestones and includes regular practice and review cycles. Dedicate time to both conceptual learning and hands-on configuration to build confidence and muscle memory.
Explore other Microsoft certifications: view all Microsoft exams.
Strengthen your preparation with up-to-date resources from validexamdumps.com. These materials align to DP-600 and cover practical scenarios with clear explanations.
Visit the exam page to download the PDF, Online Practice Test, or get a Bundle Discount offer for both formats: Implementing Analytics Solutions Using Microsoft Fabric.
Implement and manage semantic models typically accounts for the largest share of questions, as semantic model design is central to analytics solutions. However, all three domains, Prepare data, Implement and manage semantic models, and Maintain a data analytics solution, are tested equally in terms of importance to real-world job performance. Expect roughly equal coverage across all three areas.
In practice, these three areas form a continuous cycle. You prepare data to ensure quality and consistency, build semantic models on top of that prepared data to enable analytics, and then maintain the solution by monitoring performance and applying updates. Understanding how decisions in one area affect the others is critical for passing scenario-based questions and succeeding as an analytics engineer.
Hands-on experience is valuable but not strictly required if you study effectively. Prioritize labs that cover data source connections, semantic model creation, and performance monitoring. Even virtual labs or sandbox environments help you build familiarity with the Fabric interface and workflows. Aim for at least 2-3 weeks of practical work before your exam date.
Many candidates overlook the importance of row-level security and data refresh optimization, which appear frequently in scenario questions. Others confuse similar features or miss nuances in how Fabric handles incremental refresh versus full refresh. Carefully reading scenario details and understanding the "why" behind each answer prevents these costly errors.
Dedicate the first 3-4 days to reviewing weak topic areas and taking targeted practice quizzes. Spend the next 2-3 days on a full-length timed practice test and reviewing all incorrect answers. On the final day, do a light review of key definitions and common pitfalls rather than learning new material. Rest well the night before the exam.
What should you recommend using to ingest the customer data into the data store in the AnatyticsPOC workspace?
For ingesting customer data into the data store in the AnalyticsPOC workspace, a dataflow (D) should be recommended. Dataflows are designed within the Power BI service to ingest, cleanse, transform, and load data into the Power BI environment. They allow for the low-code ingestion and transformation of data as needed by Litware's technical requirements. Reference = You can learn more about dataflows and their use in Power BI environments in Microsoft's Power BI documentation.
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have a Fabric tenant that contains a semantic model named Model1.
You discover that the following query performs slowly against Model1.
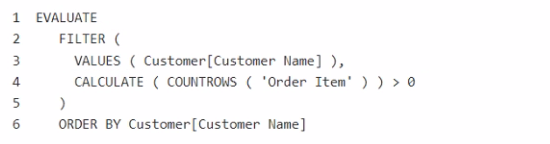
You need to reduce the execution time of the query.
Solution: You replace line 4 by using the following code:

Does this meet the goal?
You have a Fabric tenant that contains a new semantic model in OneLake.
You use a Fabric notebook to read the data into a Spark DataFrame.
You need to evaluate the data to calculate the min, max, mean, and standard deviation values for all the string and numeric columns.
Solution: You use the following PySpark expression:
df .sumary ()
Does this meet the goal?
Yes, the df.summary() method does meet the goal. This method is used to compute specified statistics for numeric and string columns. By default, it provides statistics such as count, mean, stddev, min, and max. Reference = The PySpark API documentation details the summary() function and the statistics it provides.
You have a Fabric tenant that contains a data pipeline.
You need to ensure that the pipeline runs every four hours on Mondays and Fridays.
To what should you set Repeat for the schedule?
You should set Repeat for the schedule to Weekly (C). This allows you to specify the pipeline to run on specific days of the week, in this case, every four hours on Mondays and Fridays. Reference = Scheduling options for data pipelines are available in the Azure Data Factory documentation, which includes details on configuring recurring triggers.
You are creating a semantic model in Microsoft Power Bl Desktop.
You plan to make bulk changes to the model by using the Tabular Model Definition Language (TMDL) extension for Microsoft Visual Studio Code.
You need to save the semantic model to a file.
Which file format should you use?
When saving a semantic model to a file that can be edited using the Tabular Model Scripting Language (TMSL) extension for Visual Studio Code, the PBIX (Power BI Desktop) file format is the correct choice. The PBIX format contains the report, data model, and queries, and is the primary file format for editing in Power BI Desktop. Reference = Microsoft's documentation on Power BI file formats and Visual Studio Code provides further clarification on the usage of PBIX files.