At ValidExamDumps, we consistently monitor updates to the Microsoft DP-203 exam questions by Microsoft. Whenever our team identifies changes in the exam questions,exam objectives, exam focus areas or in exam requirements, We immediately update our exam questions for both PDF and online practice exams. This commitment ensures our customers always have access to the most current and accurate questions. By preparing with these actual questions, our customers can successfully pass the Microsoft Data Engineering on Microsoft Azure exam on their first attempt without needing additional materials or study guides.
Other certification materials providers often include outdated or removed questions by Microsoft in their Microsoft DP-203 exam. These outdated questions lead to customers failing their Microsoft Data Engineering on Microsoft Azure exam. In contrast, we ensure our questions bank includes only precise and up-to-date questions, guaranteeing their presence in your actual exam. Our main priority is your success in the Microsoft DP-203 exam, not profiting from selling obsolete exam questions in PDF or Online Practice Test.
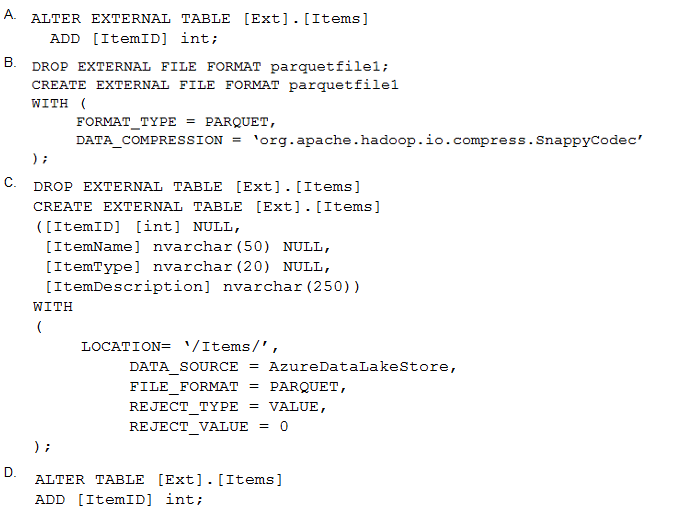
You have an enterprise data warehouse in Azure Synapse Analytics.
Using PolyBase, you create an external table named [Ext].[Items] to query Parquet files stored in Azure Data Lake Storage Gen2 without importing the data to the data warehouse.
The external table has three columns.
You discover that the Parquet files have a fourth column named ItemID.
Which command should you run to add the ItemID column to the external table?
You have several Azure Data Factory pipelines that contain a mix of the following types of activities.
* Wrangling data flow
* Notebook
* Copy
* jar
Which two Azure services should you use to debug the activities? Each correct answer presents part of the solution NOTE: Each correct selection is worth one point.
You are designing a highly available Azure Data Lake Storage solution that will induce geo-zone-redundant storage (GZRS).
You need to monitor for replication delays that can affect the recovery point objective (RPO).
What should you include m the monitoring solution?
Because geo-replication is asynchronous, it is possible that data written to the primary region has not yet been written to the secondary region at the time an outage occurs. The Last Sync Time property indicates the last time that data from the primary region was written successfully to the secondary region. All writes made to the primary region before the last sync time are available to be read from the secondary location. Writes made to the primary region after the last sync time property may or may not be available for reads yet.
https://docs.microsoft.com/en-us/azure/storage/common/last-sync-time-get
You use Azure Stream Analytics to receive Twitter data from Azure Event Hubs and to output the data to an Azure Blob storage account
You need to output the count of tweets during the last five minutes every five minutes. Each tweet must only be counted once.
Which windowing function should you use?
You haw an Azure data factory named ADF1.
You currently publish all pipeline authoring changes directly to ADF1.
You need to implement version control for the changes made to pipeline artifacts. The solution must ensure that you can apply version control to the resources currently defined m the UX Authoring canvas for ADF1.
Which two actions should you perform? Each correct answer presents part of the solution
NOTE: Each correct selection is worth one point.