The IBM C1000-130 exam validates your ability to administer IBM Cloud Pak for Integration V2021.2 in production environments. This credential is designed for IT professionals and system administrators who manage integration platforms, configure middleware components, and oversee platform governance. This page maps the exam syllabus, explains question formats, and guides your study strategy so you can approach the IBM Certified Administrator, Cloud Pak for Integration V2021.2 certification with confidence. Whether you're new to Cloud Pak for Integration or expanding your IBM skillset, the resources and guidance here help you focus on what matters most.
Use this topic map to guide your study for IBM C1000-130 (IBM Cloud Pak for Integration V2021.2 Administration) within the IBM Certified Administrator, Cloud Pak for Integration V2021.2 path.
The C1000-130 exam uses multiple question styles to assess both conceptual knowledge and practical decision-making. Items progress in difficulty and reflect real-world administration scenarios you will encounter.
Questions build in complexity and reward both breadth of knowledge across all five topic areas and depth in practical application.
Structure your study around the five core topic areas, allocating time based on your current skill level and the exam weight. A focused, weekly schedule prevents cramming and builds retention through spaced review and hands-on practice.
Explore other IBM certifications: view all IBM exams.
Strengthen your preparation with up-to-date resources from validexamdumps.com. These materials align to C1000-130 and cover practical scenarios with clear explanations.
Visit the exam page to download the PDF, Online Practice Test, or get a bundle discount for both formats: IBM Cloud Pak for Integration V2021.2 Administration.
Configuration and Platform Administration typically account for the largest portion of the exam, reflecting their importance in day-to-day administration. However, all five topic areas are tested, so balanced preparation across Planning/Installation, Governance, and Troubleshooting is essential for a strong score.
Planning and Installation establish the foundation; Configuration builds the integration flows and policies; Platform Administration ensures security and stability; Governance defines what is allowed and how to measure success; Troubleshooting addresses runtime issues. Understanding these connections helps you see the exam as a cohesive whole rather than isolated facts.
Hands-on experience is valuable for understanding how configuration choices affect behavior and for building confidence in troubleshooting scenarios. If you have access to a test environment, prioritize labs on namespace setup, API configuration, and log review. If not, study practice questions and scenario explanations carefully to simulate that experience.
Candidates often confuse similar configuration options, miss the nuance in scenario-based questions, or rush through troubleshooting items without fully reading the problem. Take time to read each question completely, eliminate obviously wrong answers, and reason through the remaining choices before selecting your answer.
In the final week, shift from learning new content to reinforcing what you know. Spend 60% of your time on full-length or half-length timed practice tests, 30% reviewing flagged questions and weak topic areas, and 10% on quick terminology and command syntax review. Avoid introducing new material; focus on confidence and accuracy.
What is the purpose of the Automation Assets Deployment capability?
In IBM Cloud Pak for Integration (CP4I) v2021.2, the Automation Assets Deployment capability is designed to help users efficiently manage integration assets within the Cloud Pak environment. This capability provides a centralized repository where users can store, manage, retrieve, and search for integration assets that are essential for automation and integration processes.
Option A is incorrect: The Automation Assets Deployment feature is not a streaming platform for managing data from multiple sources. Streaming platforms, such as IBM Event Streams, are used for real-time data ingestion and processing.
Option B is incorrect: Similar to Option A, this feature does not focus on data streaming or management from a single source but rather on handling integration assets.
Option C is correct: The Automation Assets Deployment capability provides a comprehensive solution for storing, managing, retrieving, and searching integration-related assets within IBM Cloud Pak for Integration. It enables organizations to reuse and efficiently deploy integration components across different services.
Option D is incorrect: While this capability allows for storing and managing assets, it also provides retrieval and search functionality, making Option C the more accurate choice.
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration Reference:
IBM Cloud Pak for Integration Documentation
IBM Cloud Pak for Integration Automation Assets Overview
IBM Knowledge Center -- Managing Automation Assets
What is the effect of creating a second medium size profile?
In IBM Cloud Pak for Integration (CP4I) v2021.2, profiles define the resource allocation and configuration settings for deployed services. When creating a second medium-size profile, the system will allocate the resources according to the medium-size specifications, without affecting the first profile.
Why Option B is Correct:
IBM Cloud Pak for Integration supports multiple profiles, each with its own resource allocation.
When a second medium-size profile is created, it is independently assigned the medium-size configuration without modifying the existing profiles.
This allows multiple services to run with similar resource constraints but remain separately managed.
Explanation of Incorrect Answers:
A . The first profile will be replaced by the second profile. Incorrect
Creating a new profile does not replace an existing profile; each profile is independent.
C . The first profile will be re-configured with a medium size. Incorrect
The first profile remains unchanged. A second profile does not modify or reconfigure an existing one.
D . The second profile will be configured with a large size. Incorrect
The second profile will retain the specified medium size and will not be automatically upgraded to a large size.
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration Reference:
IBM Cloud Pak for Integration Sizing and Profiles
Managing Profiles in IBM Cloud Pak for Integration
OpenShift Resource Allocation for CP4I
An API Conned administrator runs the command shown below:
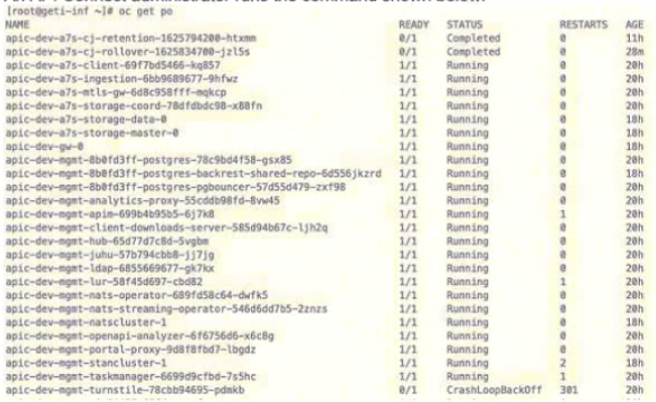
Given the output of the command, what is the state of the API Connect components?
The command executed is:
sh
CopyEdit
oc get po
This command lists the pods running in an OpenShift (OCP) cluster where IBM API Connect is deployed.
Key Observations from the Output:
Most API Connect management components (apic-dev-mgmt-xxx) are in a Running state, which indicates that the core API Connect system is operational.
The apic-dev-mgmt-turnstile pod is in a CrashLoopBackOff state, with 301 restarts, indicating that this component has repeatedly failed to start properly.
Understanding the Turnstile Component:
The Turnstile pod is a critical component of the IBM API Connect Developer Portal.
It manages authentication and access control for the Developer Portal, ensuring that API consumers can access the portal and manage API subscriptions.
When Turnstile is failing, the Developer Portal becomes unresponsive because authentication requests cannot be processed.
Why Answer B is Correct?
Since the Turnstile pod is failing, the Developer Portal will not function properly, preventing users from accessing API documentation and managing API subscriptions.
API providers and consumers will not be able to log in or interact with the Developer Portal.
Explanation of Incorrect Answers:
A . The Analytics subsystem cannot retain historical data. Incorrect
The Analytics-related pods (e.g., apic-dev-analytics-xxx) are in a Running state.
If the Analytics component were failing, metrics collection and historical API call data would be impacted, but this is not indicated in the output.
C . Automated API behavior testing has failed. Incorrect
There is no evidence in the pod list that API testing-related components (such as test clients or monitoring tools) have failed.
D . New API calls will be rejected by the gateway service. Incorrect
The gateway service is not shown as failing in the provided output.
API traffic flows through the Gateway pods (typically apic-gateway-xxx), and they appear to be running fine.
If gateway-related pods were failing, API call processing would be affected, but that is not the case here.
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration Reference:
IBM API Connect Deployment on OpenShift
Troubleshooting Developer Portal Issues
Understanding API Connect Components
OpenShift Troubleshooting Pods
OpenShift Pipelines can be used to automate the build of custom images in a CI/CD pipeline and they are based on Tekton.
What type of component is used to create a Pipeline?
OpenShift Pipelines, which are based on Tekton, use various components to define and execute CI/CD workflows. The fundamental building block for creating a Pipeline in OpenShift Pipelines is a Task.
Key Tekton Components:
Task ( Correct Answer)
A Task is the basic unit of work in Tekton.
Each Task defines a set of steps (commands) that are executed in containers.
Multiple Tasks are combined into a Pipeline to form a CI/CD workflow.
Pipeline (uses multiple Tasks)
A Pipeline is a collection of Tasks that define the entire CI/CD workflow.
Each Task in the Pipeline runs in sequence or in parallel as specified.
Why the Other Options Are Incorrect?
Option
Explanation
Correct?
A .TaskRun
Incorrect -- A TaskRun is an execution instance of a Task, but it does not define the Pipeline itself.
C . TPipe
Incorrect -- No such Tekton component called TPipe exists.
D . Pipe
Incorrect -- The correct term is Pipeline, not 'Pipe'. OpenShift Pipelines do not use this term.
Final Answer:
B . Task
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration Reference:
OpenShift Pipelines (Tekton) Documentation
Tekton Documentation -- Understanding Tasks
IBM Cloud Pak for Integration -- CI/CD with OpenShift Pipelines
OpenShift supports forwarding cluster logs to which external third-party system?
In IBM Cloud Pak for Integration (CP4I) v2021.2, which runs on Red Hat OpenShift, cluster logging can be forwarded to external third-party systems, with Splunk being one of the officially supported destinations.
OpenShift Log Forwarding Features:
OpenShift Cluster Logging Operator enables log forwarding.
Supports forwarding logs to various external logging solutions, including Splunk.
Uses the Fluentd log collector to send logs to Splunk's HTTP Event Collector (HEC) endpoint.
Provides centralized log management, analysis, and visualization.
Why Not the Other Options?
B . Kafka Broker -- OpenShift does support sending logs to Kafka, but Kafka is a message broker, not a full-fledged logging system like Splunk.
C . Apache Lucene -- Lucene is a search engine library, not a log management system.
D . Apache Solr -- Solr is based on Lucene and is used for search indexing, not log forwarding.
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration Reference
OpenShift Log Forwarding to Splunk
IBM Cloud Pak for Integration -- Logging and Monitoring
Red Hat OpenShift Logging Documentation