The Databricks Certified Professional Data Scientist Exam validates your ability to design, build, and deploy machine learning solutions on the Databricks platform. This certification is intended for data scientists who have hands-on experience with the machine learning lifecycle and want to demonstrate proficiency in applying ML techniques within production environments. This page outlines the exam syllabus, question formats, and practical preparation strategies to help you study effectively and approach the Databricks-Certified-Professional-Data-Scientist exam with confidence.
Use this topic map to guide your study for the Databricks Certified Professional Data Scientist Exam within the Data Scientist Professional path.
The Databricks Certified Professional Data Scientist Exam combines multiple-choice and scenario-based questions to assess both foundational knowledge and practical decision-making ability. Questions progress in difficulty and require you to apply concepts to realistic workflows.
Questions reflect hands-on experience and reward candidates who understand not just theory, but how to apply ML concepts in Databricks production systems.
Build a structured study plan that maps each topic to weekly milestones and incorporates both learning and practice. Effective preparation balances reading conceptual material with hands-on problem-solving and timed practice.
Explore other Databricks certifications: view all Databricks exams.
Strengthen your preparation with up‑to‑date resources from validexamdumps.com. These materials align to Databricks-Certified-Professional-Data-Scientist and cover practical scenarios with clear explanations.
Visit the exam page to download the PDF, Online Practice Test, or get a Bundle Discount offer for both formats: Databricks Certified Professional Data Scientist Exam.
Machine learning algorithms and techniques, along with the complete ML lifecycle, typically represent the largest portion of the exam. Questions emphasize your ability to apply algorithms correctly and navigate each stage of the workflow from problem definition through production deployment. Understanding model management and MLflow integration is equally important, as these reflect real-world practice on Databricks.
In practice, you begin with ML fundamentals to identify which algorithms suit your business problem. You then follow the ML lifecycle to prepare data, engineer features, and train models. Algorithm knowledge guides hyperparameter choices and evaluation strategies. Finally, model management ensures your trained model is tracked, versioned, and safely transitioned to production using MLflow. Each topic builds on the previous one and together they form a complete, reproducible workflow.
Hands-on work with Databricks notebooks, feature engineering, and MLflow model tracking is most valuable. Prioritize labs that involve training multiple models, comparing metrics, and registering models to MLflow. Practice moving models through stages (staging to production) and experiment tracking. Real experience with these workflows significantly improves both exam performance and practical confidence.
Common pitfalls include confusing when to use specific algorithms (e.g., classification vs. regression), misinterpreting evaluation metrics for imbalanced datasets, and overlooking the importance of data preprocessing in the lifecycle. Candidates also sometimes miss questions about MLflow model stage transitions or experiment tracking workflows. Careful reading of scenario details and understanding the "why" behind each technique prevents these errors.
In your final week, shift from learning new material to drilling weak areas identified in practice tests. Spend 3-4 days reviewing topic explanations and redoing missed questions. Use the remaining days for two full-length timed practice tests, reviewing each one carefully. On the day before the exam, do a light review of key definitions and algorithm characteristics rather than heavy studying. Rest well the night before to ensure mental clarity.
Select the correct statement which applies to Principal component analysis (PCA)
Suppose you have been given a relatively high-dimension set of independent variables and you are asked to come up with a model that predicts one of Two possible outcomes like "YES" or "NO", then which of the following technique best fit.
RMSE is a good measure of accuracy, but only to compare forecasting errors of different models for a______, as it is scale-dependent.
Which method is used to solve for coefficients bO, b1, ... bn in your linear regression model:
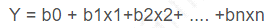
In the linear model, the bi's represent the unknown p parameters. The estimates for these unknown parameters are chosen so that, on average, the model provides a reasonable estimate of a person's income based on age and education. In other words, the fitted model should minimize the overall error between the linear model and the actual observations. Ordinary Least Squares (OLS) is a common technique to estimate the parameters