The Databricks Certified Associate Developer for Apache Spark 3.5 - Python exam validates your ability to build and optimize Apache Spark applications using Python. This certification is designed for developers who work with Databricks and need to demonstrate proficiency in Spark fundamentals, SQL operations, and DataFrame API development. This page maps the exam syllabus, explains question formats, and guides your preparation strategy. Whether you're preparing for your first attempt or refining weak areas, the resources and study plan below will help you approach the exam with confidence.
Use this topic map to guide your study for Databricks Certified Associate Developer for Apache Spark 3.5 - Python within the Apache Spark Associate Developer path.
The exam uses multiple-choice and scenario-based items to assess both conceptual knowledge and practical decision-making. Questions progress in difficulty and require you to apply Spark concepts to realistic development situations.
Questions emphasize practical application, so study with real code examples and focus on understanding not just "what" but "why" certain approaches work better in production.
A structured study plan breaks the seven topic areas into manageable weekly goals and reinforces connections between concepts. Dedicate time to hands-on practice, mock testing, and review of weak areas before exam day.
Explore other Databricks certifications: view all Databricks exams.
Strengthen your preparation with up-to-date resources from validexamdumps.com. These materials align to Databricks-Certified-Associate-Developer-for-Apache-Spark-3.5 and cover practical scenarios with clear explanations.
Visit the exam page to download the PDF, Online Practice Test, or get a bundle discount for both formats: Databricks Certified Associate Developer for Apache Spark 3.5 - Python.
DataFrame/DataSet API development and Spark SQL typically account for a larger portion of the exam because they are foundational to most Spark applications. Troubleshooting and Tuning is also heavily tested since real-world development requires performance optimization. Architecture and Structured Streaming follow, while Spark Connect and Pandas API are covered but with slightly fewer questions. Focus your deepest study on DataFrame operations and SQL to maximize your score.
In practice, you begin with Spark Architecture understanding to design your cluster, then use DataFrames or SQL to ingest and transform data. If you need real-time processing, Structured Streaming applies the same DataFrame/SQL concepts to streaming data. Spark Connect enters when you deploy the application remotely, and Pandas API may be used for specific operations where pandas syntax is more natural. Finally, Troubleshooting and Tuning is applied throughout to identify bottlenecks and improve performance. Understanding these connections helps you see the exam as a cohesive whole rather than isolated topics.
Hands-on experience is valuable because the exam includes code analysis and scenario questions that require practical understanding. Prioritize labs that let you write DataFrame transformations, execute SQL queries, and read execution plans. Structured Streaming labs are important if you haven't built streaming pipelines before. If time is limited, focus on DataFrame and SQL labs first, then move to Spark Connect deployment and tuning exercises. Even 2-3 hours of active coding per week will significantly boost your confidence on scenario-based questions.
Many candidates confuse DataFrame operations with RDD behavior or overlook how partitioning affects performance, leading to wrong optimization choices. Another frequent error is misunderstanding when to use Structured Streaming versus batch processing, or picking the wrong API (Pandas vs. native Spark) for a given scenario. Lastly, candidates sometimes rush through Troubleshooting questions without carefully reading execution plan details or error messages. Slow down on scenario questions, re-read the problem, and consider all options before selecting your answer.
In the final week, avoid trying to learn new topics; instead, do quick concept reviews and targeted practice on weak areas identified in your mock tests. Take one full-length or extended practice test under timed conditions to build pacing and reduce anxiety. Review explanations for any questions you missed, focusing on understanding the logic rather than memorizing answers. On the day before the exam, do a light review of key terminology and architecture diagrams, then rest well to arrive refreshed and focused.
A data engineer needs to write a Streaming DataFrame as Parquet files.
Given the code:

Which code fragment should be inserted to meet the requirement?
A)

B)

C)

D)

Which code fragment should be inserted to meet the requirement?
A.
.format("parquet")
.option("location", "path/to/destination/dir")
B.
CopyEdit
.option("format", "parquet")
.option("destination", "path/to/destination/dir")
C.
.option("format", "parquet")
.option("location", "path/to/destination/dir")
D.
.format("parquet")
.option("path", "path/to/destination/dir")
To write a structured streaming DataFrame to Parquet files, the correct way to specify the format and output directory is:
.writeStream
.format('parquet')
.option('path', 'path/to/destination/dir')
According to Spark documentation:
''When writing to file-based sinks (like Parquet), you must specify the path using the .option('path', ...) method. Unlike batch writes, .save() is not supported.''
Option A incorrectly uses .option('location', ...) (invalid for Parquet sink).
Option B incorrectly sets the format via .option('format', ...), which is not the correct method.
Option C repeats the same issue.
Option D is correct: .format('parquet') + .option('path', ...) is the required syntax.
Final Answer: D
A data engineer needs to persist a file-based data source to a specific location. However, by default, Spark writes to the warehouse directory (e.g., /user/hive/warehouse). To override this, the engineer must explicitly define the file path.
Which line of code ensures the data is saved to a specific location?
Options:
To persist a table and specify the save path, use:
users.write.option('path', '/some/path').saveAsTable('default_table')
The .option('path', ...) must be applied before calling saveAsTable.
Option A uses invalid syntax (write(path=...)).
Option B applies .option() after .saveAsTable()---which is too late.
Option D uses incorrect syntax (no path parameter in saveAsTable).
A data engineer is asked to build an ingestion pipeline for a set of Parquet files delivered by an upstream team on a nightly basis. The data is stored in a directory structure with a base path of "/path/events/data". The upstream team drops daily data into the underlying subdirectories following the convention year/month/day.
A few examples of the directory structure are:
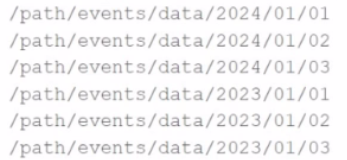
Which of the following code snippets will read all the data within the directory structure?
To read all files recursively within a nested directory structure, Spark requires the recursiveFileLookup option to be explicitly enabled. According to Databricks official documentation, when dealing with deeply nested Parquet files in a directory tree (as shown in this example), you should set:
df = spark.read.option('recursiveFileLookup', 'true').parquet('/path/events/data/')
This ensures that Spark searches through all subdirectories under /path/events/data/ and reads any Parquet files it finds, regardless of the folder depth.
Option A is incorrect because while it includes an option, inferSchema is irrelevant here and does not enable recursive file reading.
Option C is incorrect because wildcards may not reliably match deep nested structures beyond one directory level.
Option D is incorrect because it will only read files directly within /path/events/data/ and not subdirectories like /2023/01/01.
Databricks documentation reference:
'To read files recursively from nested folders, set the recursiveFileLookup option to true. This is useful when data is organized in hierarchical folder structures' --- Databricks documentation on Parquet files ingestion and options.
A developer is working with a pandas DataFrame containing user behavior data from a web application. Which approach should be used for executing a groupBy operation in parallel across all workers in Apache Spark 3.5?
A)
Use the applylnPandas API
B)

C)


The correct approach to perform a parallelized groupBy operation across Spark worker nodes using Pandas API is via applyInPandas. This function enables grouped map operations using Pandas logic in a distributed Spark environment. It applies a user-defined function to each group of data represented as a Pandas DataFrame.
As per the Databricks documentation:
'applyInPandas() allows for vectorized operations on grouped data in Spark. It applies a user-defined function to each group of a DataFrame and outputs a new DataFrame. This is the recommended approach for using Pandas logic across grouped data with parallel execution.'
Option A is correct and achieves this parallel execution.
Option B (mapInPandas) applies to the entire DataFrame, not grouped operations.
Option C uses built-in aggregation functions, which are efficient but not customizable with Pandas logic.
Option D creates a scalar Pandas UDF which does not perform a group-wise transformation.
Therefore, to run a groupBy with parallel Pandas logic on Spark workers, Option A using applyInPandas is the only correct answer.
38 of 55. A data engineer is working with Spark SQL and has a large JSON file stored at /data/input.json. The file contains records with varying schemas, and the engineer wants to create an external table in Spark SQL that:
Reads directly from /data/input.json.
Infers the schema automatically.
Merges differing schemas.
Which code snippet should the engineer use?
A.
CREATE EXTERNAL TABLE users
USING json
OPTIONS (path '/data/input.json', mergeSchema 'true');
B.
CREATE TABLE users
USING json
OPTIONS (path '/data/input.json');
C.
CREATE EXTERNAL TABLE users
USING json
OPTIONS (path '/data/input.json', inferSchema 'true');
D.
CREATE EXTERNAL TABLE users
USING json
OPTIONS (path '/data/input.json', mergeAll 'true');
To handle JSON files with evolving or differing schemas, Spark SQL supports the option mergeSchema 'true', which merges all fields across files into a unified schema.
Correct syntax:
CREATE EXTERNAL TABLE users
USING json
OPTIONS (path '/data/input.json', mergeSchema 'true');
This creates an external table directly on the JSON data, inferring schema automatically and merging variations.
Why the other options are incorrect:
B: Missing schema merge configuration --- fails with inconsistent files.
C: inferSchema applies to CSV/other file types, not JSON.
D: mergeAll is not a valid Spark SQL option.
Spark SQL Data Sources --- JSON file options (mergeSchema, path).
Databricks Exam Guide (June 2025): Section ''Using Spark SQL'' --- creating external tables and schema inference for JSON data.
===========