The ACD301 exam validates your expertise as an Appian Certified Lead Developer within the Appian Certification Program. This credential demonstrates your ability to design, build, and optimize applications on the Appian platform across enterprise environments. Whether you're advancing your career or proving hands-on mastery of Appian, this exam measures both theoretical knowledge and practical problem-solving skills. This page provides a clear study roadmap, topic breakdown, and preparation strategies to help you pass with confidence.
Use this topic map to guide your study for Appian ACD301 (Appian Certified Lead Developer) within the Appian Certification Program path.
The ACD301 exam combines multiple-choice and scenario-based items to assess both foundational knowledge and applied decision-making in real-world Appian contexts.
Questions progress in difficulty and emphasize practical judgment over memorization, reflecting how lead developers solve problems in production environments.
Build a structured study plan that maps each topic to weekly goals and includes hands-on practice. Allocate more time to Application Design and Development and Proactively Design for Scalability and Performance, as these domains typically carry greater weight on the exam.
Explore other Appian certifications: view all Appian exams.
Strengthen your preparation with up-to-date resources from validexamdumps.com. These materials align to ACD301 and cover practical scenarios with clear explanations.
Visit the exam page to download the PDF, Online Practice Test, or get a Bundle Discount offer for both formats: Appian Certified Lead Developer.
Application Design and Development and Proactively Design for Scalability and Performance typically account for the largest portion of exam questions. These domains test your core ability to architect and optimize Appian solutions. However, all six topics are important; a balanced study approach ensures you're prepared for any question type.
In practice, these domains overlap significantly. You start with Project and Resource Management to plan the initiative, move into Application Design and Development to build interfaces and processes, use Data Management to structure and integrate data, apply Proactively Design for Scalability and Performance to optimize performance, use Extending Appian to add custom capabilities, and rely on Platform Management to deploy and maintain the solution. Understanding these connections helps you answer scenario-based questions more effectively.
The exam assumes you have at least 12-18 months of professional Appian development experience. Hands-on work with real projects is more valuable than theoretical study alone. Prioritize labs and exercises that let you configure processes, design data models, and optimize queries in actual Appian environments.
Many candidates underestimate the importance of performance optimization and scalability questions, focusing instead on basic feature knowledge. Others struggle with scenario items because they don't connect concepts across domains. Additionally, rushing through questions without fully reading the context or constraints leads to selecting plausible but suboptimal answers. Take time to understand the business requirement before choosing your response.
In your final week, shift from learning new content to reinforcing weak areas and building confidence. Spend 60% of your time on practice tests and reviewing explanations, 30% on targeted review of difficult topics, and 10% on light reading of key definitions and best practices. Avoid cramming new material; instead, focus on solidifying what you've already learned and building test-day rhythm.
A customer wants to integrate a CSV file once a day into their Appian application, sent every night at 1:00 AM. The file contains hundreds of thousands of items to be used daily by users as soon as their workday starts at 8:00 AM. Considering the high volume of data to manipulate and the nature of the operation, what is the best technical option to process the requirement?
Comprehensive and Detailed In-Depth Explanation:
As an Appian Lead Developer, handling a daily CSV integration with hundreds of thousands of items requires a solution that balances performance, scalability, and Appian's architectural strengths. The timing (1:00 AM integration, 8:00 AM availability) and data volume necessitate efficient processing and minimal runtime overhead. Let's evaluate each option based on Appian's official documentation and best practices:
A . Use an Appian Process Model, initiated after every integration, to loop on each item and update it to the business requirements:
This approach involves parsing the CSV in a process model and using a looping mechanism (e.g., a subprocess or script task with fn!forEach) to process each item. While Appian process models are excellent for orchestrating workflows, they are not optimized for high-volume data processing. Looping over hundreds of thousands of records would strain the process engine, leading to timeouts, memory issues, or slow execution---potentially missing the 8:00 AM deadline. Appian's documentation warns against using process models for bulk data operations, recommending database-level processing instead. This is not a viable solution.
B . Build a complex and optimized view (relevant indices, efficient joins, etc.), and use it every time a user needs to use the data:
This suggests loading the CSV into a table and creating an optimized database view (e.g., with indices and joins) for user queries via a!queryEntity. While this improves read performance for users at 8:00 AM, it doesn't address the integration process itself. The question focuses on processing the CSV (''manipulate'' and ''operation''), not just querying. Building a view assumes the data is already loaded and transformed, leaving the heavy lifting of integration unaddressed. This option is incomplete and misaligned with the requirement's focus on processing efficiency.
C . Create a set of stored procedures to handle the volume and the complexity of the expectations, and call it after each integration:
This is the best choice. Stored procedures, executed in the database, are designed for high-volume data manipulation (e.g., parsing CSV, transforming data, and applying business logic). In this scenario, you can configure an Appian process model to trigger at 1:00 AM (using a timer event) after the CSV is received (e.g., via FTP or Appian's File System utilities), then call a stored procedure via the ''Execute Stored Procedure'' smart service. The stored procedure can efficiently bulk-load the CSV (e.g., using SQL's BULK INSERT or equivalent), process the data, and update tables---all within the database's optimized environment. This ensures completion by 8:00 AM and aligns with Appian's recommendation to offload complex, large-scale data operations to the database layer, maintaining Appian as the orchestration layer.
D . Process what can be completed easily in a process model after each integration, and complete the most complex tasks using a set of stored procedures:
This hybrid approach splits the workload: simple tasks (e.g., validation) in a process model, and complex tasks (e.g., transformations) in stored procedures. While this leverages Appian's strengths (orchestration) and database efficiency, it adds unnecessary complexity. Managing two layers of processing increases maintenance overhead and risks partial failures (e.g., process model timeouts before stored procedures run). Appian's best practices favor a single, cohesive approach for bulk data integration, making this less efficient than a pure stored procedure solution (C).
Conclusion: Creating a set of stored procedures (C) is the best option. It leverages the database's native capabilities to handle the high volume and complexity of the CSV integration, ensuring fast, reliable processing between 1:00 AM and 8:00 AM. Appian orchestrates the trigger and integration (e.g., via a process model), while the stored procedure performs the heavy lifting---aligning with Appian's performance guidelines for large-scale data operations.
Appian Documentation: 'Execute Stored Procedure Smart Service' (Process Modeling > Smart Services).
Appian Lead Developer Certification: Data Integration Module (Handling Large Data Volumes).
Appian Best Practices: 'Performance Considerations for Data Integration' (Database vs. Process Model Processing).
You are required to configure a connection so that Jira can inform Appian when specific tickets change (using a webhook). Which three required steps will allow you to connect both systems?
Comprehensive and Detailed In-Depth Explanation:
Configuring a webhook connection from Jira to Appian requires setting up a mechanism for Jira to push ticket change notifications to Appian in real-time. This involves creating an endpoint in Appian to receive the webhook and configuring Jira to send the data. Appian's Integration Best Practices and Web API documentation provide the framework for this process.
Option A (Create a Web API object and set up the correct security):
This is a required step. In Appian, a Web API object serves as the endpoint to receive incoming webhook requests from Jira. You must define the API structure (e.g., HTTP method, input parameters) and configure security (e.g., basic authentication, API key, or OAuth) to validate incoming requests. Appian recommends using a service account with appropriate permissions to ensure secure access, aligning with the need for a controlled webhook receiver.
Option B (Configure the connection in Jira specifying the URL and credentials):
This is essential. In Jira, you need to set up a webhook by providing the Appian Web API's URL (e.g., https://
Option C (Create a new API Key and associate a service account):
This is necessary for secure authentication. Appian recommends using an API key tied to a service account for webhook integrations. The service account should have permissions to process the incoming data (e.g., write to a process or data store) but not excessive privileges. This step complements the Web API security setup and Jira configuration.
Option D (Give the service account system administrator privileges):
This is unnecessary and insecure. System administrator privileges grant broad access, which is overkill for a webhook integration. Appian's security best practices advocate for least-privilege principles, limiting the service account to the specific objects or actions needed (e.g., executing the Web API).
Option E (Create an integration object from Appian to Jira to periodically check the ticket status):
This is incorrect for a webhook scenario. Webhooks are push-based, where Jira notifies Appian of changes. Creating an integration object for periodic polling (pull-based) is a different approach and not required for the stated requirement of Jira informing Appian via webhook.
These three steps (A, B, C) establish a secure, functional webhook connection without introducing unnecessary complexity or security risks.
The three required steps that will allow you to connect both systems are:
A . Create a Web API object and set up the correct security. This will allow you to define an endpoint in Appian that can receive requests from Jira via webhook. You will also need to configure the security settings for the Web API object, such as authentication method, allowed origins, and access control.
B . Configure the connection in Jira specifying the URL and credentials. This will allow you to set up a webhook in Jira that can send requests to Appian when specific tickets change. You will need to specify the URL of the Web API object in Appian, as well as any credentials required for authentication.
C . Create a new API Key and associate a service account. This will allow you to generate a unique token that can be used for authentication between Jira and Appian. You will also need to create a service account in Appian that has permissions to access or update data related to Jira tickets.
The other options are incorrect for the following reasons:
D . Give the service account system administrator privileges. This is not required and could pose a security risk, as giving system administrator privileges to a service account could allow it to perform actions that are not related to Jira tickets, such as modifying system settings or accessing sensitive data.
As part of an upcoming release of an application, a new nullable field is added to a table that contains customer dat
a. The new field is used by a report in the upcoming release and is calculated using data from another table.
Which two actions should you consider when creating the script to add the new field?
Comprehensive and Detailed In-Depth Explanation:
As an Appian Lead Developer, adding a new nullable field to a database table for an upcoming release requires careful planning to ensure data integrity, report functionality, and rollback capability. The field is used in a report and calculated from another table, so the script must handle both deployment and potential reversibility. Let's evaluate each option:
A . Create a script that adds the field and leaves it null:
Adding a nullable field and leaving it null is technically feasible (e.g., using ALTER TABLE ADD COLUMN in SQL), but it doesn't address the report's need for calculated data. Since the field is used in a report and calculated from another table, leaving it null risks incomplete or incorrect reporting until populated, delaying functionality. Appian's data management best practices recommend populating data during deployment for immediate usability, making this insufficient as a standalone action.
B . Create a rollback script that removes the field:
This is a critical action. In Appian, database changes (e.g., adding a field) must be reversible in case of deployment failure or rollback needs (e.g., during testing or PROD issues). A rollback script that removes the field (e.g., ALTER TABLE DROP COLUMN) ensures the database can return to its original state, minimizing risk. Appian's deployment guidelines emphasize rollback scripts for schema changes, making this essential for safe releases.
C . Create a script that adds the field and then populates it:
This is also essential. Since the field is nullable, calculated from another table, and used in a report, populating it during deployment ensures immediate functionality. The script can use SQL (e.g., UPDATE table SET new_field = (SELECT calculated_value FROM other_table WHERE condition)) to populate data, aligning with Appian's data fabric principles for maintaining data consistency. Appian's documentation recommends populating new fields during deployment for reporting accuracy, making this a key action.
D . Create a rollback script that clears the data from the field:
Clearing data (e.g., UPDATE table SET new_field = NULL) is less effective than removing the field entirely. If the deployment fails, the field's existence with null values could confuse reports or processes, requiring additional cleanup. Appian's rollback strategies favor reverting schema changes completely (removing the field) rather than leaving it with nulls, making this less reliable and unnecessary compared to B.
E . Add a view that joins the customer data to the data used in calculation:
Creating a view (e.g., CREATE VIEW customer_report AS SELECT ... FROM customer_table JOIN other_table ON ...) is useful for reporting but isn't a prerequisite for adding the field. The scenario focuses on the field addition and population, not reporting structure. While a view could optimize queries, it's a secondary step, not a primary action for the script itself. Appian's data modeling best practices suggest views as post-deployment optimizations, not script requirements.
Conclusion: The two actions to consider are B (create a rollback script that removes the field) and C (create a script that adds the field and then populates it). These ensure the field is added with data for immediate report usability and provide a safe rollback option, aligning with Appian's deployment and data management standards for schema changes.
Appian Documentation: 'Database Schema Changes' (Adding Fields and Rollback Scripts).
Appian Lead Developer Certification: Data Management Module (Schema Deployment Strategies).
Appian Best Practices: 'Managing Data Changes in Production' (Populating and Rolling Back Fields).
You need to connect Appian with LinkedIn to retrieve personal information about the users in your application. This information is considered private, and users should allow Appian to retrieve their information. Which authentication method would you recommend to fulfill this request?
Comprehensive and Detailed In-Depth Explanation:
As an Appian Lead Developer, integrating with an external system like LinkedIn to retrieve private user information requires a secure, user-consented authentication method that aligns with Appian's capabilities and industry standards. The requirement specifies that users must explicitly allow Appian to access their private data, which rules out methods that don't involve user authorization. Let's evaluate each option based on Appian's official documentation and LinkedIn's API requirements:
A . API Key Authentication:
API Key Authentication involves using a single static key to authenticate requests. While Appian supports this method via Connected Systems (e.g., HTTP Connected System with an API key header), it's unsuitable here. API keys authenticate the application, not the user, and don't provide a mechanism for individual user consent. LinkedIn's API for private data (e.g., profile information) requires per-user authorization, which API keys cannot facilitate. Appian documentation notes that API keys are best for server-to-server communication without user context, making this option inadequate for the requirement.
B . Basic Authentication with user's login information:
This method uses a username and password (typically base64-encoded) provided by each user. In Appian, Basic Authentication is supported in Connected Systems, but applying it here would require users to input their LinkedIn credentials directly into Appian. This is insecure, impractical, and against LinkedIn's security policies, as it exposes user passwords to the application. Appian Lead Developer best practices discourage storing or handling user credentials directly due to security risks (e.g., credential leakage) and maintenance challenges. Moreover, LinkedIn's API doesn't support Basic Authentication for user-specific data access---it requires OAuth 2.0. This option is not viable.
C . Basic Authentication with dedicated account's login information:
This involves using a single, dedicated LinkedIn account's credentials to authenticate all requests. While technically feasible in Appian's Connected System (using Basic Authentication), it fails to meet the requirement that ''users should allow Appian to retrieve their information.'' A dedicated account would access data on behalf of all users without their individual consent, violating privacy principles and LinkedIn's API terms. LinkedIn restricts such approaches, requiring user-specific authorization for private data. Appian documentation advises against blanket credentials for user-specific integrations, making this option inappropriate.
D . OAuth 2.0: Authorization Code Grant:
This is the recommended choice. OAuth 2.0 Authorization Code Grant, supported natively in Appian's Connected System framework, is designed for scenarios where users must authorize an application (Appian) to access their private data on a third-party service (LinkedIn). In this flow, Appian redirects users to LinkedIn's authorization page, where they grant permission. Upon approval, LinkedIn returns an authorization code, which Appian exchanges for an access token via the Token Request Endpoint. This token enables Appian to retrieve private user data (e.g., profile details) securely and per user. Appian's documentation explicitly recommends this method for integrations requiring user consent, such as LinkedIn, and provides tools like a!authorizationLink() to handle authorization failures gracefully. LinkedIn's API (e.g., v2 API) mandates OAuth 2.0 for personal data access, aligning perfectly with this approach.
Conclusion: OAuth 2.0: Authorization Code Grant (D) is the best method. It ensures user consent, complies with LinkedIn's API requirements, and leverages Appian's secure integration capabilities. In practice, you'd configure a Connected System in Appian with LinkedIn's Client ID, Client Secret, Authorization Endpoint (e.g., https://www.linkedin.com/oauth/v2/authorization), and Token Request Endpoint (e.g., https://www.linkedin.com/oauth/v2/accessToken), then use an Integration object to call LinkedIn APIs with the access token. This solution is scalable, secure, and aligns with Appian Lead Developer certification standards for third-party integrations.
Appian Documentation: 'Setting Up a Connected System with the OAuth 2.0 Authorization Code Grant' (Connected Systems).
Appian Lead Developer Certification: Integration Module (OAuth 2.0 Configuration and Best Practices).
LinkedIn Developer Documentation: 'OAuth 2.0 Authorization Code Flow' (API Authentication Requirements).
You are on a protect with an application that has been deployed to Production and is live with users. The client wishes to increase the number of active users.
You need to conduct load testing to ensure Production can handle the increased usage
Review the specs for four environments in the following image.
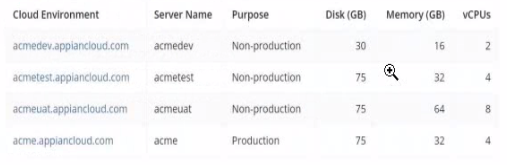
Which environment should you use for load testing7
The image provides the specifications for four environments in the Appian Cloud:
acmedev.appiancloud.com (acmedev): Non-production, Disk: 30 GB, Memory: 16 GB, vCPUs: 2
acmetest.appiancloud.com (acmetest): Non-production, Disk: 75 GB, Memory: 32 GB, vCPUs: 4
acmeuat.appiancloud.com (acmeuat): Non-production, Disk: 75 GB, Memory: 64 GB, vCPUs: 8
acme.appiancloud.com (acme): Production, Disk: 75 GB, Memory: 32 GB, vCPUs: 4
Load testing assesses an application's performance under increased user load to ensure scalability and stability. Appian's Performance Testing Guidelines emphasize using an environment that mirrors Production as closely as possible to obtain accurate results, while avoiding direct impact on live systems.
Option A (acmeuat): This is the best choice. The UAT (User Acceptance Testing) environment (acmeuat) has the highest resources (64 GB memory, 8 vCPUs) among the non-production environments, closely aligning with Production's capabilities (32 GB memory, 4 vCPUs) but with greater capacity to handle simulated loads. UAT environments are designed to validate the application with real-world usage scenarios, making them ideal for load testing. The higher resources also allow testing beyond current Production limits to predict future scalability, meeting the client's goal of increasing active users without risking live data.
Option B (acmedev): The development environment (acmedev) has the lowest resources (16 GB memory, 2 vCPUs), which is insufficient for load testing. It's optimized for development, not performance simulation, and results would not reflect Production behavior accurately.
Option C (acme): The Production environment (acme) is live with users, and load testing here would disrupt service, violate Appian's Production Safety Guidelines, and risk data integrity. It should never be used for testing.
Option D (acmetest): The test environment (acmetest) has moderate resources (32 GB memory, 4 vCPUs), matching Production's memory and vCPUs. However, it's typically used for SIT (System Integration Testing) and has less capacity than acmeuat. While viable, it's less ideal than acmeuat for simulating higher user loads due to its resource constraints.
Appian recommends using a UAT environment for load testing when it closely mirrors Production and can handle simulated traffic, making acmeuat the optimal choice given its superior resources and non-production status.